
Is Seeing Believing? A Look into Deepfakes
Original Release Date: 3/3/2021
Deepfakes are images, videos, or audio recordings that have been synthetically produced by artificial intelligence (AI) algorithms. They are manipulated and altered versions of an original medium. New items or people may be inserted, the actions of individuals may be modified, and the audio of an individual may be changed, all while maintaining the smooth and realistic appearance of the medium. In fact, deepfake technology has advanced to the point where viewers are unlikely to know the difference between a deepfake and a real piece of media content. For example, a team of researchers at Cornell recently developed an AI program that generated faces of people who do not exist. When viewing the material without any context, the images appear to be actual people due to the hyper-realistic details of each face.
Deepfakes - and their more common counterpart, cheapfakes - are becoming more prevalent in the world today. While deepfakes are AI-manipulated media, cheapfakes are media that have been manipulated through cheaper and more accessible means, such as commercial photo and video editing software. Despite their low-tech and unsophisticated nature, cheapfakes can also trick viewers and serve as an avenue for disinformation. For example, a video of the US Speaker of the House Nancy Pelosi that surfaced in 2019 was found to have been a slowed version of the original video with the intention of making the Speaker appear impaired and drunk. Despite its inauthenticity, it received millions of views and shares on popular social media sites.
How Are Deepfakes Made?
One of the ways to manipulate faces in a video is through the use of an autoencoder, which is a specific type of neural network. Neural networks are one of the tools used in machine learning, whereby a computer learns to accomplish a task after having been provided a large set of data. For more information on neural networks and machine learning, please review the NJCCIC post Seeing AI to AI: Artificial Intelligence and its Impact on Cybersecurity. To better understand deepfakes, we first need to understand that neural networks consist of different layers: an input layer, followed by a number of hidden layers in which the computer processes data and performs computations, and an output layer. The input layer consists of thousands of pictures of both the face of the original person in the video and the face of the person that will be swapped in to replace the original person. The original person in the video will be referred to as Person A and the person whose face will be swapped into the video will be referred to as Person B. Autoencoders can be divided into two parts - the encoder, which makes up the left half of the neural network shown on the left side of the image below, and the decoder, which makes up the right half of the image. The purpose of the encoder is to find some compressed representation of the input images, essentially learning the important features of the face of both Person A and Person B. Then, the decoder tries to reconstruct the face from this compressed representation. By comparing the original and reconstructed faces, the autoencoder learns to find a more optimal compressed representation and improve its encoding and decoding algorithms.
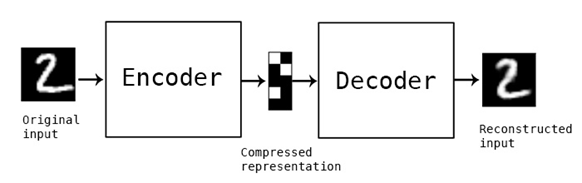
Image Source: The Keras Blog
But how does the encoder work? Recall that neural networks consist of different layers, with different algorithms being computed between each layer. An in-depth look into the first few layers helps explain the inner workings of the encoder. The first hidden layer of the encoder looks at patches of the image, known as windows. For example, by looking at every 3x3 window of pixels in the image, rather than every single pixel individually, the computer can identify basic features, such as horizontal lines. We can also tell the model to slide this window by a predefined number of pixels - known as the stride - to the right, downwards, or in another direction. The figure below illustrates the layer of the encoder and how the layer performs some computation on a 3x3 window of pixels rather than pixel by pixel, relative to the size of the window. In addition, if the window slides one pixel to the right and downwards, the stride is defined as 1 pixel.
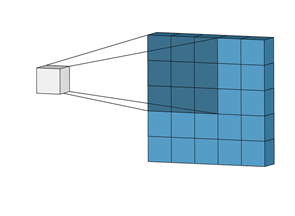
Image Source: Towards Data Science
The number of filters is also defined for each window, or the number of locally defined and spatially invariant features in these windows. For instance, we may search for the presence of both horizontal lines and vertical lines. If there is a single feature, like shown above, then there is a single “sheet” of data that makes up the next layer of the neural network. However, if there are multiple features, then there are multiple “sheets” making up the next layer, as shown below. These sheets of data can be simplified through a process called pooling. One strategy, for example, is average pooling, where the computer collapses each sheet of data into smaller sheets of data by representing each window of the previous layer’s sheet of data with a single number - the average of all data points in the window.
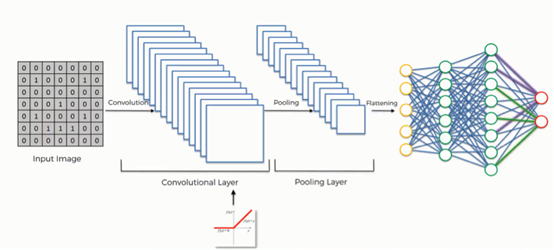
Image Source: SuperDataScience
Autoencoders are a specific type of neural networks, known as convolutional neural networks. The process of obtaining multiple sheets of data by looking at a different number of features results in what is known as a convolutional layer, as shown in the image above.
This process repeats in the encoder, extracting more high-level features from previous layers. For example, perhaps the first layer identified two features of the image - horizontal and vertical lines - using two different filters. The second layer, then, might attempt to identify whether squares are in the image by using both of the two sheets of data of the previous layer, which indicates the presence of horizontal and vertical lines. The encoder stops when it reaches a predefined number of features for the decoder to reconstruct the original face.
The decoder then takes over, attempting to reconstruct the input from the lower-dimensional layer of the compressed representation of the input image. The reconstruction process can be thought of as the mirror image of the encoder. First, the autoencoder compares the output of the decoder with the original input. Then, based on the differences between these two images, the computations and parameters used between the layers of the autoencoder are modified. The end goal is to develop a neural network that produces an output image that is very similar to the original image.
The autoencoder is trained on both sets of images - the faces of Person A (the original person in the video) and the faces of Person B (the person whose face will replace that of Person A). During the training process, the same encoder is used for both Person A and Person B, but different decoders are used for each person, as shown below.
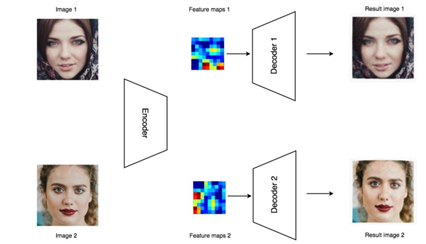
Image Source: Medium
Once the model is trained, the production of the deepfake starts. The face of Person A is fed into the decoder for every frame of the video; however, rather than using the decoder constructed for Person A, the decoder that the computer developed for Person B is used instead. This process is the most important step that makes deepfakes so realistic. Person B’s face is constructed using the features of Person A’s face at a particular frame of the video. By repeating this process for every frame, a video is created with Person B’s face on Person A’s body. Of course, the accuracy and realism of the deepfake depends on the number of training images during the training phase of the model; the more pictures used for training, the longer the training phase. In addition, while better results can be obtained by making the model and algorithms more complex, it would require more computational power and time. While autoencoders may be the most accessible method to produce a deepfake, there are many other methods under active research. For example, another specific type of machine learning, known as generative adversarial networks (GANs), has recently produced much more realistic results. A team at Cornell used a model to develop faces that do not exist. However, due to the complexity and computational power this model requires, GANs have not been used extensively outside of academic research.
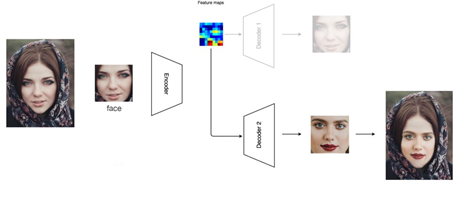
Image Source: Medium
What Are the Dangers of Deepfakes?
Deepfakes can serve as an avenue for malware. For example, threat actors may send emails claiming to have access to deepfakes and convince them to click on malicious attachments, programs, or links. Emails or social media posts can also include deepfakes of well-known figures, including celebrities, politicians, or CEOs, and attempt to extract personal and/or financial information. For instance, the message could include a deepfake of a politician soliciting donations or requesting credit card numbers and other sensitive or financial information. In 2019, cybercriminals were able to spoof the voice of the CEO of a German company using AI-based software and successfully stole about $243,000 from a UK-based energy firm. Although this was the first cybercrime reported to have used AI, experts predict that there will be an increase in AI-based cyberattacks in the future, including social engineering attacks based on deepfakes.
Additionally, deepfakes can also be used to extort individuals. Threat actors may harass their targets with deepfakes and threaten to release the doctored media if a monetary demand is not met. Trend Micro reported the potential for threat actors to adopt “next-generation sextortion scams'' into their ransomware campaigns, pressuring their targets to pay by a certain deadline. If the targets miss the deadline, the threat actors would send out the incriminating deepfakes to all of the target’s contacts. A similar extortion tactic includes using deepfakes of a targeted individual to convince their family members that the individual has been taken hostage and will only be released in exchange for money.
Furthermore, one of the most concerning dangers of deepfakes is their ability to spread disinformation. With deepfake technology developing rapidly, it is already difficult to distinguish a real video from a deepfake. In fact, both deepfakes and cheapfakes have caused physical damage and have even led to deaths due to the disinformation spread. Even if deepfakes do not cause physical harm directly, they can be used to negatively impact an individual’s reputation. Although most existing deepfakes are adult content-related, deepfakes can also target specific individuals. Celebrities and politicians can be targeted using deepfakes created from the countless number of images available online, and these deepfakes may show the target engaging in inappropriate or otherwise detrimental behavior. Deepfake-based revenge porn can also cause to major impacts to a person's life and impact their reputation and public image.
Leading experts also warn against the potential misuse of deepfakes against democratic institutions. The 2019 World Threat Assessment produced by the Office of the Director of National Intelligence explicitly highlights the dangers of deepfakes, warning that “adversaries and strategic competitors probably will attempt to use deep fakes or similar machine-learning technologies to create convincing - but false - image, audio, and video files to augment influence campaigns against the United States and our allies and partners.” Moreover, the blur between fact and fiction can lead to the abuse of plausible deniability by high-profile politicians. Whenever authentic videos and images damaging to an individual’s reputation are released, a politician may immediately reject the media, claiming that the video and audio were fake and are products of deepfake-based AI programs. As a result, citizens can lose trust of their politicians and governmental institutions, endangering the very foundation of democracies.
Even with a reliable method to detect deepfakes, any country that is politically polarized serves as a conducive environment for deepfakes to further divide a society. In fact, the identification of a video as a deepfake may have no effect for heavily partisan individuals who trust the video even before viewing it. This can produce a snowballing effect, as more of these citizens rely on partisan media sources rather than independent, quality-based media sources, leading to less control against deepfakes.
How Can We Identify Deepfakes?
Although deepfake technology has greatly advanced in the last several years, it is still possible for anyone to identify less sophisticated deepfakes. When viewing an image or video, many deepfakes can be identified by the following signs:
- Flickering, especially in the outlines of the face/hair or when the face changes angles
- Inconsistency in skin color and texture
- Unusually consistent or lacking variability, such as a strangely perfect hairline or teeth
- Strange blinking patterns
- Lips/mouth are out of sync with the person’s speech
It is important to view media content hosted on trusted websites; otherwise, viewers are advised to question the validity of the media by analyzing whether the image or video shows people involved in typical behavior. Public awareness is another key element to increase users’ knowledge of and the ability to identify deepfakes.
What Do We Do If We Observe a Deepfake?
- Deepfakes intending to be viewed as legitimate media should not be shared.
- Although it is unlikely for a deepfake of low-profile individuals to exist due to the lack of training data (available images/videos), there is still the possibility that one exists. This type of deepfake is usually inappropriate in nature with the intention to spread online and negatively impact the target’s reputation.
- Immediately contact the vendor and/or website that hosts the deepfake.
- At this time, there is no unified state-level or federal-level regulation governing the proper reporting procedures of deepfakes; however, Congress is currently reviewing a number of promising bills, including the Deepfake Report Act of 2019 and House Resolution 3230, that will address the problems caused by deepfakes. Similar bills have also been introduced to the New Jersey legislature.
- Practice basic cyber hygiene to reduce the risk of being victimized.
- Updating social media privacy settings ensures only authorized and trusted individuals have access to your photos and videos. Although typically effective, it will not completely prevent access to multiple images for deepfake creations. In addition, even a lack of training data may not prevent deepfake creations since a recent AI program developed by Samsung demonstrated a deepfake creation from just a single profile picture. Other best practices include exercising caution with communications received from unknown senders and refraining from clicking on links or opening attachments.
- Verify legitimacy.
- Always verify calls for donations or other charity contributions and If you receive a communication that claims you won a prize or reward, a loved one is in danger, or threatens to release deepfake videos or images, refrain from providing information, money, or access to your devices and notify the NJCCIC and/or your local police department.
Further information can be found in the following video "Creating, Weaponizing, and Detecting Deep Fakes" from Hany Farid, university professor who specializes in the analysis of digital images.

The NJCCIC is a component organization within the New Jersey Office of Homeland Security and Preparedness. We are the State's one-stop-shop for cyber threat analysis, incident reporting, and information sharing and are committed to making New Jersey more resilient to cyber threats by spreading awareness and promoting the adoption of best practices.





View our Privacy Policy here.
View our Site Index here.